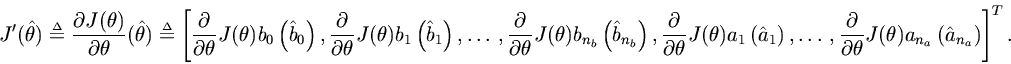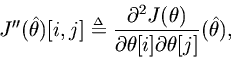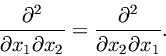NOTE: THIS DOCUMENT IS OBSOLETE, PLEASE CHECK THE NEW VERSION: "Introduction to Digital Filters with Audio Applications", by Julius O. Smith III, Copyright © 2017-11-26 by Julius O. Smith III - Center for Computer Research in Music and Acoustics (CCRMA), Stanford University
<< Previous page TOC INDEX Next page >>
Gradient Descent
Concavity is valuable in connection with the Gradient Method of minimizing
with respect to
.
Definition. The gradient of the error measure
column vector
Definition. The Gradient Method (Cauchy) is defined as follows.
Given
, compute
whereis the gradient of
at
, and
is chosen as the smallest nonnegative local minimizer of
Cauchy originally proposed to find the value ofwhich gave a global minimum of
. This, however, is not always feasible in practice.
Some general results regarding the Gradient Method are given below.
Theorem. If
is a local minimizer of
exists, then
.
Theorem. The gradient method is a descent method, i.e.,
.
Definition.
,
, is said to be in the class
if all
th order partial derivatives of
.
Definition. The Hessian
of
wheredenotes the
th component of
,
, and
denotes the matrix entry at the
th column.
The Hessian of every element of
is a symmetric matrix [Williamson et al. 1972]. This is because continuous second-order partials satisfy
Theorem. If
, then any cluster point
of the gradient sequence
.
Theorem. Let
denote the concave hull of
, and there exist positive constants
and
such that
for alland for all
, then the gradient method beginning with any point in
. Moreover,
.
By the norm equivalence theorem [Ortega 1972], Eq. (5) is satisfied whenever
belongs to